 Catalogue PIGMA
Catalogue PIGMA
2025
Type of resources
Available actions
Topics
Keywords
Contact for the resource
Provided by
Years
Formats
Representation types
Update frequencies
status
Scale
Resolution
-

This visualization product displays the density of floating micro-litter per net normalized per km² per year from research and monitoring protocols. EMODnet Chemistry included the collection of marine litter in its 3rd phase. Before 2021, there was no coordinated effort at the regional or European scale for micro-litter. Given this situation, EMODnet Chemistry proposed to adopt the data gathering and data management approach as generally applied for marine data, i.e., populating metadata and data in the CDI Data Discovery and Access service using dedicated SeaDataNet data transport formats. EMODnet Chemistry is currently the official EU collector of micro-litter data from Marine Strategy Framework Directive (MSFD) National Monitoring activities (descriptor 10). A series of specific standard vocabularies or standard terms related to micro-litter have been added to SeaDataNet NVS (NERC Vocabulary Server) Common Vocabularies to describe the micro-litter. European micro-litter data are collected by the National Oceanographic Data Centres (NODCs). Micro-litter map products are generated from NODCs data after a test of the aggregated collection including data and data format checks and data harmonization. A filter is applied to represent only micro-litter sampled according to research and monitoring protocols as MSFD monitoring. Densities were calculated for each net using the following calculation: Density (number of particles per km²) = Micro-litter count / (Sampling effort (km) * Net opening (cm) * 0.00001) When information about the sampling effort (km) was lacking and point coordinates were known (start and end of the sampling), the sampling effort was calculated using the PostGIS ST_DistanceSpheroid function with a WGS84 measurement spheroid. When the number of micro-litters or the net opening was not filled, it was not possible to calculate the density. Percentiles 50, 75, 95 & 99 have been calculated taking into account data for all years. Warning: the absence of data on the map does not necessarily mean that they do not exist, but that no information has been entered in the National Oceanographic Data Centre (NODC) for this area.
-

This visualization product displays the cigarette related items abundance of marine macro-litter (> 2.5cm) per beach per year from Marine Strategy Framework Directive (MSFD) monitoring surveys without UNEP-MARLIN data. EMODnet Chemistry included the collection of marine litter in its 3rd phase. Since the beginning of 2018, data of beach litter have been gathered and processed in the EMODnet Chemistry Marine Litter Database (MLDB). The harmonization of all the data has been the most challenging task considering the heterogeneity of the data sources, sampling protocols and reference lists used on a European scale. Preliminary processings were necessary to harmonize all the data: - Exclusion of OSPAR 1000 protocol: in order to follow the approach of OSPAR that it is not including these data anymore in the monitoring; - Selection of MSFD surveys only (exclusion of other monitoring, cleaning and research operations); - Exclusion of beaches without coordinates; - Selection of cigarette related items only. The list of selected items is attached to this metadata. This list was created using EU Marine Beach Litter Baselines, the European Threshold Value for Macro Litter on Coastlines and the Joint list of litter categories for marine macro-litter monitoring from JRC (these three documents are attached to this metadata); - Selection of surveys referring to the UNEP-MARLIN list: the UNEP-MARLIN protocol differs from the other types of monitoring in that cigarette butts are surveyed in a 10m square. To avoid comparing abundances from very different protocols, the choice has been made to distinguish in two maps the cigarette related items results associated with the UNEP-MARLIN list from the others; - Normalization of survey lengths to 100m & 1 survey / year: in some case, the survey length was not exactly 100m, so in order to be able to compare the abundance of litter from different beaches a normalization is applied using this formula: Number of cigarette related items of the survey (normalized by 100 m) = Number of cigarette related items of the survey x (100 / survey length) Then, this normalized number of cigarette related items is summed to obtain the total normalized number of cigarette related items for each survey. Finally, the median abundance of cigarette related items for each beach and year is calculated from these normalized abundances of cigarette related items per survey. Sometimes the survey length was null or equal to 0. Assuming that the MSFD protocol has been applied, the length has been set at 100m in these cases. Percentiles 50, 75, 95 & 99 have been calculated taking into account cigarette related items from MSFD monitoring data (excluding UNEP-MARLIN protocol) for all years. More information is available in the attached documents. Warning: the absence of data on the map does not necessarily mean that they do not exist, but that no information has been entered in the Marine Litter Database for this area.
-

Moving 6-year analysis of Water body silicate in the Mediterranean Sea for each season: - winter: January-March, - spring: April-June, - summer: July-September, - autumn: October-December. Every year of the time dimension corresponds to the 6-year centered average of the season. 6-years periods span from 1970-1975 until 2018-2023. Description of DIVA analysis: The computation was done with the DIVAnd (Data-Interpolating Variational Analysis in n dimensions), version 2.7.12, using GEBCO 30sec topography for the spatial connectivity of water masses. The horizontal resolution of the produced DIVAnd maps grids is dx=dy=0.125 degrees (around 13.5km and 10.9km accordingly). The vertical resolution is 25 depth levels: [0.,5.,10.,20.,30.,50.,75.,100.,125.,150.,200.,250.,300.,400.,500.,600.,700.,800.,900.,1000.,1100.,1200.,1300.,1400.,1500.]. The horizontal correlation length is 200km. The vertical correlation length (in meters) was set twices the vertical resolution: [10.,10.,20.,20.,40.,50.,50.,50.,50.,100.,100.,100.,200.,200.,200.,200.,200.,200.,200.,200.,200.,200.,200.,200.,200.]. Duplicates check was performed using the following criteria for space and time: dlon=0.001deg., dlat=0.001deg., ddepth=1m, dtime=1hour, dvalue=0.1. The error variance (epsilon2) was set equal to 1 for profiles and 10 for time series to reduce the influence of close data near the coasts. An anamorphosis transformation was applied to the data (function DIVAnd.Anam.loglin) to avoid unrealistic negative values: threshold value=200. A background analysis field was used for all years (1970-2023) with correlation length equal to 600km and error variance (epsilon2) equal to 20. Quality control of the observations was applied using the interpolated field (QCMETHOD=3). Residuals (differences between the observations and the analysis (interpolated linearly to the location of the observations) were calculated. Observations with residuals outside the minimum and maximum values of the 99% quantile were discarded from the analysis. Originators of Italian data sets-List of contributors: - Brunetti Fabio (OGS) - Cardin Vanessa, Bensi Manuel doi:10.6092/36728450-4296-4e6a-967d-d5b6da55f306 - Cardin Vanessa, Bensi Manuel, Ursella Laura, Siena Giuseppe doi:10.6092/f8e6d18e-f877-4aa5-a983-a03b06ccb987 - Cataletto Bruno (OGS) - Cinzia Comici Cinzia (OGS) - Civitarese Giuseppe (OGS) - DeVittor Cinzia (OGS) - Giani Michele (OGS) - Kovacevic Vedrana (OGS) - Mosetti Renzo (OGS) - Solidoro C.,Beran A.,Cataletto B.,Celussi M.,Cibic T.,Comici C.,Del Negro P.,De Vittor C.,Minocci M.,Monti M.,Fabbro C.,Falconi C.,Franzo A.,Libralato S.,Lipizer M.,Negussanti J.S.,Russel H.,Valli G., doi:10.6092/e5518899-b914-43b0-8139-023718aa63f5 - Celio Massimo (ARPA FVG) - Malaguti Antonella (ENEA) - Fonda Umani Serena (UNITS) - Bignami Francesco (ISAC/CNR) - Boldrini Alfredo (ISMAR/CNR) - Marini Mauro (ISMAR/CNR) - Miserocchi Stefano (ISMAR/CNR) - Zaccone Renata (IAMC/CNR) - Lavezza, R., Dubroca, L. F. C., Ludicone, D., Kress, N., Herut, B., Civitarese, G., Cruzado, A., Lefèvre, D.,Souvermezoglou, E., Yilmaz, A., Tugrul, S., and Ribera d'Alcala, M.: Compilation of quality controlled nutrient profiles from the Mediterranean Sea, doi:10.1594/PANGAEA.771907, 2011.
-

'''DEFINITION''' Ocean heat content (OHC) is defined here as the deviation from a reference period (1993-2014) and is closely proportional to the average temperature change from z1 = 0 m to z2 = 700 m depth: OHC=∫_(z_1)^(z_2)ρ_0 c_p (T_yr-T_clim )dz [1] with a reference density of = 1030 kgm-3 and a specific heat capacity of cp = 3980 J kg-1 °C-1 (e.g. von Schuckmann et al., 2009). Time series of annual mean values area averaged ocean heat content is provided for the Mediterranean Sea (30°N, 46°N; 6°W, 36°E) and is evaluated for topography deeper than 300m. '''CONTEXT''' Knowing how much and where heat energy is stored and released in the ocean is essential for understanding the contemporary Earth system state, variability and change, as the oceans shape our perspectives for the future. The quality evaluation of MEDSEA_OMI_OHC_area_averaged_anomalies is based on the “multi-product” approach as introduced in the second issue of the Ocean State Report (von Schuckmann et al., 2018), and following the MyOcean’s experience (Masina et al., 2017). Six global products and a regional (Mediterranean Sea) product have been used to build an ensemble mean, and its associated ensemble spread. The reference products are: • The Mediterranean Sea Reanalysis at 1/24 degree horizontal resolution (MEDSEA_MULTIYEAR_PHY_006_004, DOI: https://doi.org/10.25423/CMCC/MEDSEA_MULTIYEAR_PHY_006_004_E3R1, Escudier et al., 2020) • Four global reanalyses at 1/4 degree horizontal resolution (GLOBAL_MULTIYEAR_PHY_ENS_001_031): GLORYS, C-GLORS, ORAS5, FOAM • Two observation based products: CORA (INSITU_GLO_PHY_TS_OA_MY_013_052) and ARMOR3D (MULTIOBS_GLO_PHY_TSUV_3D_MYNRT_015_012). Details on the products are delivered in the PUM and QUID of this OMI. '''CMEMS KEY FINDINGS''' The ensemble mean ocean heat content anomaly time series over the Mediterranean Sea shows a continuous increase in the period 1993-2022 at rate of 1.38±0.08 W/m2 in the upper 700m. After 2005 the rate has clearly increased with respect the previous decade, in agreement with Iona et al. (2018). '''DOI (product):''' https://doi.org/10.48670/moi-00261
-

This visualization product displays the density of floating micro-litter per net normalized per m³ per year from specific protocols different from research and monitoring protocols. EMODnet Chemistry included the collection of marine litter in its 3rd phase. Before 2021, there was no coordinated effort at the regional or European scale for micro-litter. Given this situation, EMODnet Chemistry proposed to adopt the data gathering and data management approach as generally applied for marine data, i.e., populating metadata and data in the CDI Data Discovery and Access service using dedicated SeaDataNet data transport formats. EMODnet Chemistry is currently the official EU collector of micro-litter data from Marine Strategy Framework Directive (MSFD) National Monitoring activities (descriptor 10). A series of specific standard vocabularies or standard terms related to micro-litter have been added to SeaDataNet NVS (NERC Vocabulary Server) Common Vocabularies to describe the micro-litter. European micro-litter data are collected by the National Oceanographic Data Centres (NODCs). Micro-litter map products are generated from NODCs data after a test of the aggregated collection including data and data format checks and data harmonization. A filter is applied to represent only micro-litter sampled according to a very specific protocol such as the Volvo Ocean Race (VOR) or Oceaneye. Densities were calculated for each net using the following calculation: Density (number of particles per m³) = Micro-litter count / Sampling effort (m³) When the number of micro-litters was not filled, it was not possible to calculate the density. Percentiles 50, 75, 95 & 99 have been calculated taking into account data for all years. Warning: the absence of data on the map does not necessarily mean that they do not exist, but that no information has been entered in the National Oceanographic Data Centre (NODC) for this area.
-

This visualization product displays marine macro-litter (> 2.5cm) material categories percentages per beach per year from the Marine Strategy Framework Directive (MSFD) monitoring surveys. EMODnet Chemistry included the collection of marine litter in its 3rd phase. Since the beginning of 2018, data of beach litter have been gathered and processed in the EMODnet Chemistry Marine Litter Database (MLDB). The harmonization of all the data has been the most challenging task considering the heterogeneity of the data sources, sampling protocols and reference lists used on a European scale. Preliminary processings were necessary to harmonize all the data: - Exclusion of OSPAR 1000 protocol: in order to follow the approach of OSPAR that it is not including these data anymore in the monitoring; - Selection of MSFD surveys only (exclusion of other monitoring, cleaning and research operations); - Exclusion of beaches without coordinates; - Some litter types like organic litter, small fragments (paraffin and wax; items > 2.5cm) and pollutants have been removed. The list of selected items is attached to this metadata. This list was created using EU Marine Beach Litter Baselines, the European Threshold Value for Macro Litter on Coastlines and the Joint list of litter categories for marine macro-litter monitoring from JRC (these three documents are attached to this metadata); - Exclusion of the "feaces" category: it concerns more exactly the items of dog excrements in bags of the OSPAR (item code: 121) and ITA (item code: IT59) reference lists; - Normalization of survey lengths to 100m & 1 survey / year: in some case, the survey length was not exactly 100m, so in order to be able to compare the abundance of litter from different beaches a normalization is applied using this formula: Number of items (normalized by 100 m) = Number of litter per items x (100 / survey length) Then, this normalized number of items is summed to obtain the total normalized number of litter for each survey. Sometimes the survey length was null or equal to 0. Assuming that the MSFD protocol has been applied, the length has been set at 100m in these cases. To calculate the percentage for each material category, formula applied is: Material (%) = (∑number of items (normalized at 100 m) of each material category)*100 / (∑number of items (normalized at 100 m) of all categories) The material categories differ between reference lists (OSPAR, ITA, TSG-ML, UNEP, UNEP-MARLIN, JLIST). In order to apply a common procedure for all the surveys, the material categories have been harmonized. More information is available in the attached documents. Warning: the absence of data on the map does not necessarily mean that they do not exist, but that no information has been entered in the Marine Litter Database for this area.
-

This dataset contains the dynamical outputs of a global ocean simulation coupling dynamics and biogeochemistry at ¼° over the year 2019. The simulation has been performed using the coupled circulation/ecosystem model NEMO/PISCES (https://www.nemo-ocean.eu/), which is here enhanced to perform an ensemble simulation with explicit simulation of modeling uncertainties in the physics and in the biogeochemistry. This dataset is one of the 40 members of the ensemble simulation. This study was part of the Horizon Europe project SEAMLESS (https://seamlessproject.org/Home.html), with the general objective of improving the analysis and forecast of ecosystem indicators. See Popov et al. (https://os.copernicus.org/articles/20/155/2024/) for more details on the study.
-

The Southern Ocean plays a fundamental role in regulating the global climate. This ocean also contains a rich and highly productive ecosystem, potentially vulnerable to climate change. Very large national and international efforts are directed towards the modeling of physical oceanographic processes to predict the response of the Southern Ocean to global climate change and the role played by the large-scale ocean climate processes. However, these modeling efforts are greatly limited by the lack of in situ measurements, especially at high latitudes and during winter months. The standard data that are needed to study ocean circulation are vertical profiles of temperature and salinity, from which we can deduce the density of seawater. These are collected with CTD (Conductivity-Temperature-Depth) sensors that are usually deployed on research vessels or, more recently, on autonomous Argo profilers. The use of conventional research vessels to collect these data is very expensive, and does not guarantee access to areas where sea ice is found at the surface of the ocean during the winter months. A recent alternative is the use of autonomous Argo floats. However, this technology is not easy to use in glaciated areas. In this context, the collection of hydrographic profiles from CTDs mounted on marine mammals is very advantageous. The choice of species, gender or age can be done to selectively obtain data in particularly under-sampled areas such as under the sea ice or on continental shelves. Among marine mammals, elephant seals are particularly interesting. Indeed, they have the particularity to continuously dive to great depths (590 ± 200 m, with maxima around 2000 m) for long durations (average length of a dive 25 ± 15 min, maximum 80 min). A Conductivity-Temperature-Depth Satellite Relay Data Logger (CTD-SRDLs) has been developed in the early 2000s to sample temperature and salinity vertical profiles during marine mammal dives (Boehme et al. 2009, Fedak 2013). The CTD-SRDL is attached to the seal on land, then it records hydrographic profiles during its foraging trips, sending the data by satellite ARGOS whenever the seal goes back to the surface.While the principle intent of seal instrumentation was to improve understanding of seal foraging strategies (Biuw et al., 2007), it has also provided as a by-product a viable and cost-effective method of sampling hydrographic properties in many regions of the Southern Ocean (Charrassin et al., 2008; Roquet et al., 2013).
-
Ensemble simulations of the ecosystem model Apecosm (https://apecosm.org) forced by the IPSL-CM6-LR climate model with the climate change scenario SSP5-8.5. The output files contain yearly mean biomass density for 3 communities (epipelagic, mesopelagic migratory and mesopelagic redidents) and 100 size classes (ranging from 0.12cm to 1.96m) The model grid file is also provided. Units are in J/m2 and can be converted in kg/m2 by dividing by 4e6. These outputs are associated with the "Assessing the time of emergence of marine ecosystems from global to local scales using IPSL-CM6A-LR/APECOSM climate-to-fish ensemble simulations" paper from the Earth's Future "Past and Future of Marine Ecosystems" Special Collection.
-
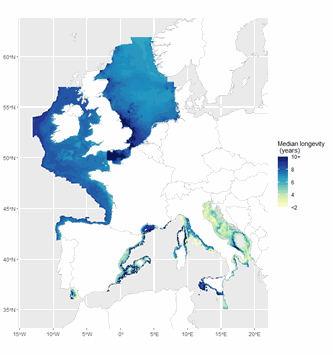
The ICES Working Group on Fisheries Benthic Impact and Trade-offs (WGFBIT) has developed an assessment framework based on the life history trait longevity, to evaluate the benthic impact of fisheries at the regional scale. In order to apply this framework to the Mediterranean sea, several Mediterranean longevity databases were merged together with existing North-East Atlantic ones to develop a common database. Longevity was fuzzy coded into four longevity classes: <1, 1-3, 3-10 and >10 years. Both benthic mega and macrofauna organisms are included in this dataset. Further details about both the purpose and the methodology may be found in ICES (2022) and Cuyvers et al. (2023). The result of the final dataset merging is one dataset containing the fuzzy coded average longevity (and standard deviation) for 2264 taxa and for each, the number of databases used.