 Catalogue PIGMA
Catalogue PIGMA
dataset
Type of resources
Available actions
Topics
Keywords
Contact for the resource
Provided by
Years
Formats
Representation types
Update frequencies
status
Scale
Resolution
-

-
Périmètre de la CAPB
-
-
Auteur(s): Darteyron Bernard , Projet d'un centre de thermalisme en milieu rural dans le département des Landes sur quatre communes voisines de Dax
-

Ce document se décompose en deux parties: La première énonce les valeurs et fonctions du massif forestier communes à tous les acteurs concernés par son avenir. La seconde présente les pressions et les enjeux qui pèsent sur le massif forestier des Landes de Gascogne.
-
Auteur(s): Bonnet Annie - Crego Andre, Une cité lacustre à Biscarrosse.
-
Le référentiel inondation Gironde (RIG) est un outil d’aide à la décision. Il vise à apporter une connaissance précise des caractéristiques morphologiques du territoire et une modélisation hydraulique des principaux phénomènes dynamiques de crue influençant directement les inondations sur l'estuaire de la Gironde. L'objectif est ainsi de permettre à l’ensemble des partenaires d’orienter des études en vue d’améliorer ou d’optimiser la protection et la gestion des zones inondables du territoire. Le RIG, modèle hydraulique, s'appuie sur un jeu important de données (topographie, bathymétrie, digues, ouvrages, foncier, marégrammes, orientation du vent, etc.).
-

The in-situ TAC integrates and quality control in a homogeneous manner in situ data from outside Copernicus Marine Environment Monitoring Service (CMEMS) data providers to fit the needs of internal and external users. It provides access to integrated datasets of core parameters for initialization, forcing, assimilation and validation of ocean numerical models which are used for forecasting, analysis and re-analysis of ocean physical and biogeochemical conditions. The in-situ TAC comprises a global in-situ centre and 6 regional in-situ centres (one for each EuroGOOS ROOSs). The focus of the CMEMS in-situ TAC is on parameters that are presently necessary for Copernicus Monitoring and Forecasting Centres namely temperature, salinity, sea level, current, waves, chlorophyll / fluorescence, oxygen and nutrients. The initial focus has been on observations from autonomous observatories at sea (e.g. floats, buoys, gliders, ferrybox, drifters, and ships of opportunity). The second objective was to integrate products over the past 25 to 50 years for re-analysis purposes... Gathering data from outsider organisations requires strong mutual agreements. Integrating data into ONE data base requires strong format standard definition and quality control procedures. The complexity of handling in situ observation depends not only on the wide range of sensors that have been used to acquire them but, in addition to that, the different operational behaviour of the platforms (i.e vessels allow on board human supervision, while the supervision of others should be put off until recovering or message/ping reception)°
-
Auteur(s): Féchant Charles , Partant du constat de la rupture urbaine et du déséquilibre entre les deux rives de la Garonne à Bordeaux, l'auteur s'interroge sur les moyens de transformer le fleuve, espace vide et facteur de séparation, en un élément positif de réunification de la ville. L'idée est d'aménager une place publique sur le fleuve-même afin de modifier les limites matérielles, visuelles, psychologiques qui régissent depuis trop longtemps ce territoire.
-
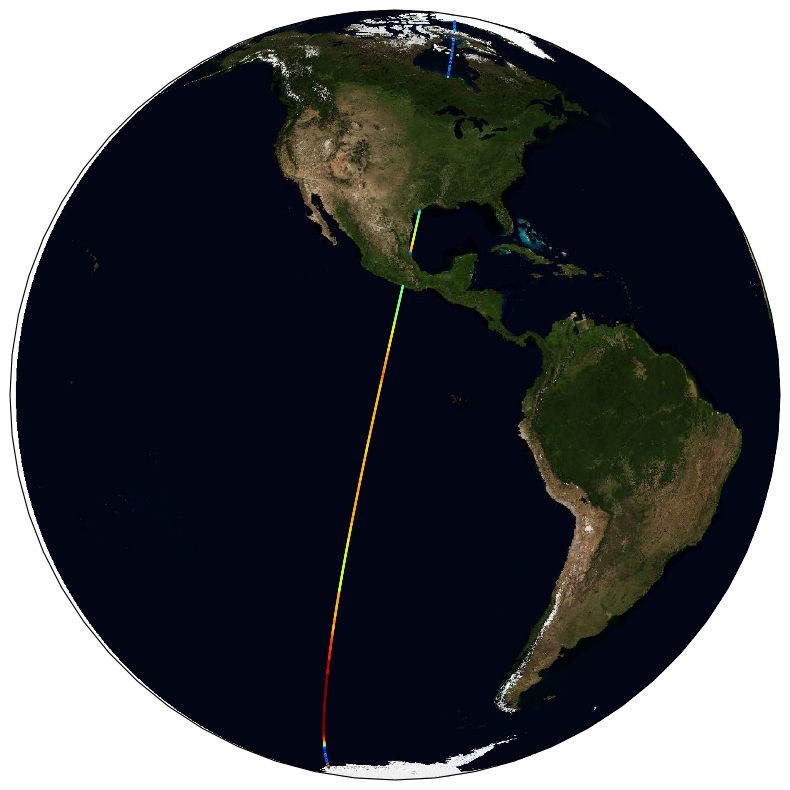
The ESA Sea State Climate Change Initiative (CCI) project has produced global multi-sensor time-series of along-track satellite altimeter significant wave height data (referred to as Level 2P (L2P) data) with a particular focus for use in climate studies. This dataset contains the Version 3 Remote Sensing Significant Wave Height product, which provides along-track data at approximately 6 km spatial resolution, separated per satellite and pass, including all measurements with flags, corrections and extra parameters from other sources. These are expert products with rich content and no data loss. The altimeter data used in the Sea State CCI dataset v3 come from multiple satellite missions spanning from 2002 to 2022021 (Envisat, CryoSat-2, Jason-1, Jason-2, Jason-3, SARAL, Sentinel-3A), therefore spanning over a shorter time range than version 1.1. Unlike version 1.1, this version 3 involved a complete and consistent retracking of all the included altimeters. Many altimeters are bi-frequency (Ku-C or Ku-S) and only measurements in Ku band were used, for consistency reasons, being available on each altimeter but SARAL (Ka band).